


Syntax
Grep [pattern] [filename]
After using grep, there comes a pattern. The pattern implies the way we want to use it in removing extra space in the data. Following the pattern, the filename is described through which the pattern is performed.
Prerequisite
To understand the usefulness of grep easily, we need to have Ubuntu installed on our system. Provide user details by providing username and password to have privileges in accessing the applications of Linux. After logging in, open the application and search for a terminal or apply the shortcut key of ctrl+alt+T.
By Using [: blank:] Keyword
Suppose we have a file named bfile having a text extension. You can create a file either on text editor or with a command line in the terminal. To create a file on the terminal, including the following commands.
There is no need to create a file if it is already present. Just display it using the appended command:
Text written in these files contains spaces between them, as seen in the figure below.

These blank lines can be removed using a blank command to ignore empty spaces between the words or strings.
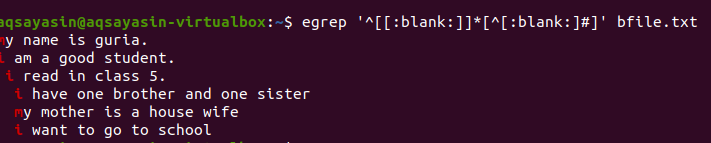
After applying the query, the blank spaces between the lines will be removed, and the output will no longer contain extra space. The first word is highlighted as spaces between the last word of the line and between the first words of the next line are removed. We can also apply conditions on the same grep command by adding this blank function to remove useless space in the output.
By Using [: space:]
Another example of ignoring space is explained here.
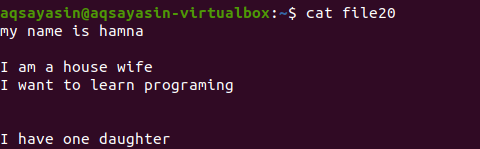
Without mentioning file extension, we will first display the existing file using the command.
Let’s look at how extra space is removed using the grep command besides the [: space:] keyword. Grep’s –v option will help print lines that lack blank lines and extra spacing that is also included in a paragraph form.
You will see that extra lines are removed and output is in sequenced form line-wise. That’s how grep –v methodology is so helpful in obtaining the required goal.

Mentioning file extensions limit the grep functionality to perform only on the particular file extensions, i.e., .text or .mp3. As we perform an alignment on a text file, we will take fileg.txt as a sample file. First, we will display the text present in it using the $ cat function. Output is as follow:

By applying the command, our output file has been obtained. Here, we can see data without spacing between the lines that are consecutively written.

Besides long commands, we can also go with the short written commands in Linux and Unix to implement grep supports shorthand characters in it.
We have seen how the output is obtained by applying commands from the input. Here, we will learn how input is maintained back from the output.
Here we will use a temporary text file with extension of text named as tmp.
By Using ^#
Just like other examples described, we will apply the command on the text file using the cat command. We can also display text using the echo command.
The text file includes 4 lines in it, having space between them. These space lines are easily removed using a particular command.

Regular extended operations are enabled by –E, which allows all regular expressions, especially pipe. A pipe is used as an optional “or” condition in any pattern.”^#”. This shows the matching of text lines in the file that begins with the sign #. “^$” will match with all free spaces in the text or blank lines.
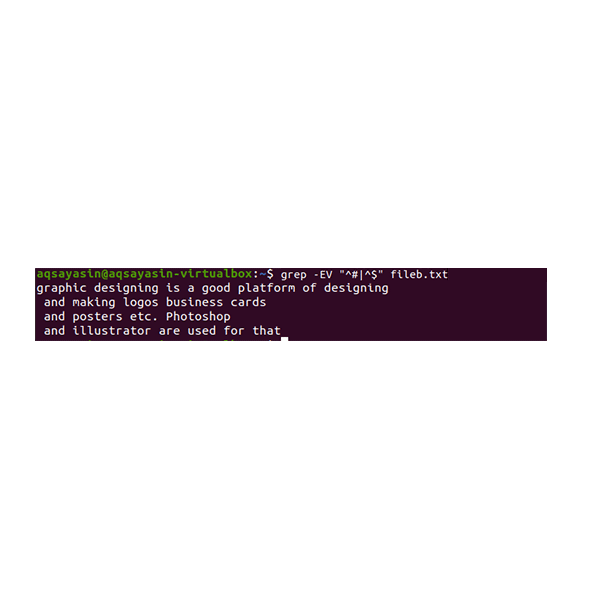
The output shows the complete removal of extra space between the lines present in the data file. In this example, we have seen that in the command that ”^#” comes first, which means the text is matched first. “^$” comes after | operator, so free space is matched afterward.
By Using ^$
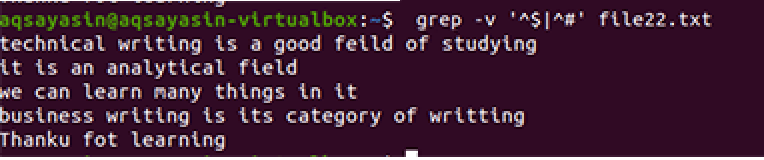
Just like the example mentioned above, we will come with the same results because the command is almost the same. However, the pattern is written oppositely. File22.txt is a file, which we are going to use in removing spaces.

The same methodology is applied except the working with priority. According to this command, first, free spaces will be matched, then the text files are matched. The output will provide a sequence of lines by removing extra gaps in them.
Other Simple Commands
- Grep ‘^. .’ filename.
- Grep ‘.’ Filename
These both are so simple and helps in removing gaps in text lines.
Conclusion
Removing useless gaps in files with the help of regular expressions is quite an easy approach to achieve a smooth sequence of data and maintain consistency. Examples are explained in a detailed manner to enhance your information regarding the topic.
from Linux Hint https://ift.tt/3gvQOT1



0 Comments