


The most popular Python library which is utilized in data science is called Pandas. It offers Python programmers high-performance, user-friendly, and data analysis tools. Once you understand the fundamental functions and how to utilize them, Pandas is a potent tool for altering data. In “pandas” the standard methods for storing data in a tabular form are the DataFrames. We can utilize some “pandas” methods for getting the unique values in the “pandas” DataFrame’s column. When we need to get unique values in the DataFrame’s columns and don’t want duplication of values in the “pandas” DataFrame’s column, we can use the methods that “pandas” provides for doing this. Let’s look at such methods in this guide, along with some examples and output to get unique values in the DataFrame’s column of “pandas”.
Methods for Getting Unique Values in “pandas” DataFrame’s Columns
We can utilize two methods for getting the unique values in the “pandas” DataFrame’s columns. We drop the duplicate values and only get the unique values in the columns of DataFrames. The methods that “pandas” provide for doing this task are:
- By utilizing the unique() method.
- By utilizing the drop_dupliactes() method.
Now, we will utilize both methods in the “pandas” codes for getting the unique values in the “pandas” DataFrame’s columns.
Example # 01
The “Spyder” app is utilized here for generating these “pandas” codes to utilize those methods which help us in getting the unique values in the “pandas” DataFrame’s columns. We must import the “pandas” modules, which are necessary for the “pandas” code, before creating the DataFrame. By using the term “import” and placing “pandas as pd,” we import these modules.
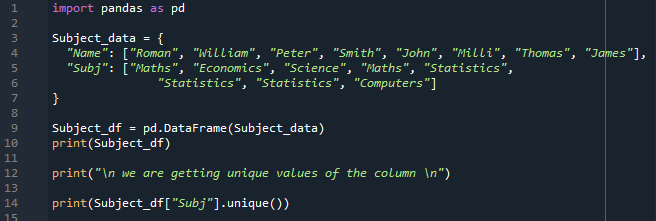
Now, with the aid of “pd”, we can quickly obtain the “pandas” functions or methods. We then put the “Subject_data” in which we add “Name” and in the “Name”, we are adding the name’s data which are “Roman, William, Peter, Smith, John, Milli, Thomas, and James”. Then, we add the subject data in the “Subj” which are “Maths, Economics, Science, Maths, Statistics, Statistics, Statistics, and Computer”. Then, we convert this “Subject_data” into the “Subject_df” DataFrame by using the “pd.DataFrame()” method. We place “Subject_df” in the “print()” method so it will show on the terminal.
Now, we want to get the unique values in the “pandas” DataFrame’s column “Subj”. For this purpose, we are using the “unique()” method here and we add the name of the column and also the name of the DataFrame as shown below. We add this method in the “print()” so the result will also show on the terminal.
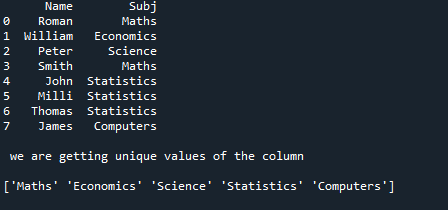
Now, we are pressing the “Shift+Enter” for getting the result of this code and it renders on the terminal and is also shown here, which contains the DataFrame with all values. This is the original DataFrame that we have added in the code and below it displays the unique values of the “Subj” column. It drops the duplicate values and displays the unique values of the “Subj” column of the DataFrame.
Example # 02
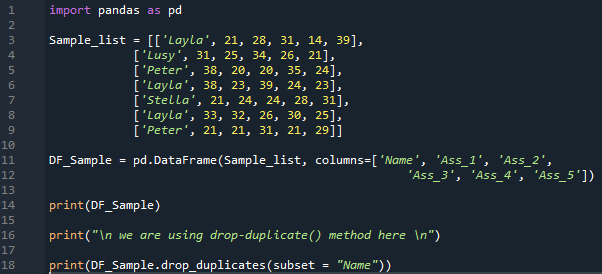
We create the “Sample_list” which contains some information. We insert “Layla, 21, 28, 31, 14, and 39” which will appear as the first column when we convert this list into the DataFrame. Then, we add “Lusy, 31, 25, 34, 26, and 21” as the second row of the DataFrame. After this, we have “Peter, 38, 20, 20, 35, and 24” and “Layla 38, 23, 39 24, 23” which will be the third and fourth rows of the DataFrame. We also insert three more data which are “Stella, 21, 24, 24, 28, 31”, “Layla, 33, 32, 26, 30, 25” and also “Peter, 21, 21, 31, 21, 29”.
Now, we are converting the “Sample_list” into the “DF_Sample” which is the name of the DataFrame here by putting the “pd.DataFrame()” function. Also, we set the name of the columns of this DataFrame and these names are “Name, Ass_1, Ass_2, Ass_3, Ass_4, and Ass_5”. Then, we use the “print()” which helps in displaying the DataFrame “DF_Sample”. Now, we are using another method in this example for getting the unique values in the DataFrame’s column. This method is the “drop_duplicates()” method of “pandas”.
In the “drop_duplicates()” method, we set the name of the column where we want to get the unique values in the DataFrame’s column. We are getting unique values of the “Name” column by dropping the duplicate values in this column with the help of the “drop_duplicates()” method and also render these unique values using the “print()” function here.
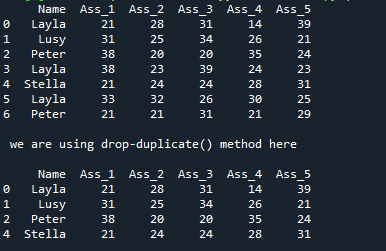
The names which are duplicated are dropped and unique values are rendered after applying the “drop_duplicates()” method. You can note that the “Layla” name appears in three cells of the “Name” column. But when the “drop_duplicates()” method is applied to this column, all duplicate values are dropped and one “Layla” name has appeared on the screen. After dropping the duplicate values, the new DataFrame appeared which contains the unique values in this “Name” column. In this way, we can drop the duplicate values and get the unique value in the DataFrame’s column with the help of the “drop_duplicates()” method.
Example # 03
The same DataFrame is utilized again and now we are applying the “unique()” method here. With the “unique()” method we place the name of the column as well as the DataFrame’s name on which we want to apply this “unique()” method for getting the unique values. This will only render the unique values of that column and will not show these values in the form of DataFrame.
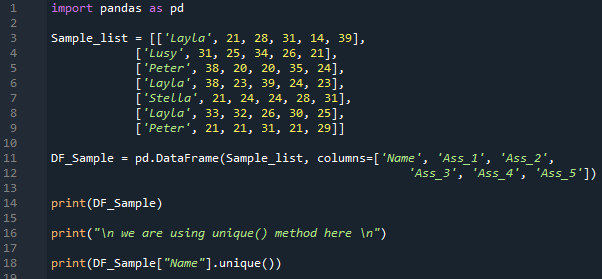
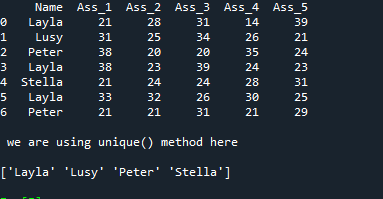
Here, the DataFrame contains seven values in the “Name” column but when we apply the “unique()” method to this column, only four values have appeared and these are the unique values of that column. It doesn’t render duplicate values.
Example # 04
The DataFrame which we create in this example is the “F_G_df”. We insert “My_fruits” and “my_Vegs” in this DataFrame. The “My_fruits” column contains “Apple, Orange, Apple, Pear, Lychee, Apple, Apple, Pear, and Apple”. Next, we have the “My_Vegs” which contains the names of the vegetables which are “Chilli, Bringle, Carrot, Potato, Potato, Carrot, Onion, Garlic, and Ginger”. This DataFrame contains only two columns.
Now, we are getting the unique values in both columns with the help of the “unique()” method. We mention the name of the DataFrame. Then, put the column first column name. After this, we utilize the append() method. In this append, we again place the name of the DataFrame and the second column name and place the “unique()” method. This will get the unique values of both columns and then append the unique values of both columns and appear them on the screen.
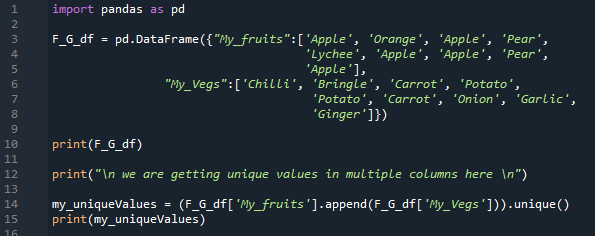
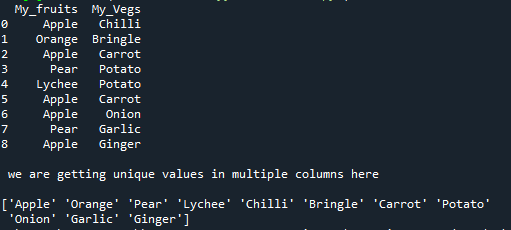
The DataFrame is rendered first containing all values. After this, the “unique()” method is applied and the unique values of both columns are rendered below. In this code, we get the unique values in the multiple columns of the DataFrame by using the “unique()” method.
Conclusion
The full explanation of getting the unique values in the DataFrame’s column is found in this guide. We have discussed the “unique()” and the “drop_duplicates()” methods which helps us in getting the unique values of the DataFrame’s column. We have explored how to use these methods in the “pandas” code by using these methods here in our codes. We’ve illustrated different examples in this guide and have shown you how to get the unique values of one column by using the “unique()” method as well as the “drop_duplicates()” method. We have also explored how to get the unique values in multiple columns by utilizing the “unique()” method in this guide.
from https://ift.tt/w6sCgdW



0 Comments