


There is a fundamental need to categorize or rank various records when working with data. For example, you could rank teams based on their scores, employees based on their salary, and many more.
Most of us perform calculations using functions that return a single value. In this guide, we will explore how to use the SQL Server rank function to return an aggregate value for a specific row group.
SQL Server Rank() Function: The Basics
The rank() function is part of SQL Server window functions. It works by assigning a rank to each row for a specific partition of the resulting set.
The function assigns the same rank value for the rows within a similar partition. It assigns the first rank, the value of 1, and adds a consecutive value to each rank.
The syntax for the rank function is as:
[partition BY expression],
ORDER BY expression [ASC|DESC]
);
Let us break down the above syntax.
The partition by clause divides rows into specific partitions where the rank function is applied. For example, in a database containing employee data, you can partition rows based on the departments in which they work.
The next clause, ORDER BY, defines the order in which the rows are organized in the specified partitions.
SQL Server Rank() Function: Practical Usage
Let us take a practical example to understand how to use the rank() function in SQL Server.
Start by creating a sample table containing employee information.
id INT IDENTITY(1,1), NOT a NULL PRIMARY KEY,
name VARCHAR(200) NOT NULL,
department VARCHAR(50),
salary money
);
Next, add some data to the table:
VALUES ('Rebecca', 'Game Developer',$120000 ),
('James', 'Mobile Developer', $110000),
('Laura', 'DevOps Developer', $180000),
('Quill', 'Mobile Developer', $109000),
('John', 'Full-Stack Developer', $182000),
('Matthew', 'Game Developer', $140000),
('Caitlyn', 'DevOps Developer',$123000),
('Michelle', 'Data Science Developer', $204000),
('Antony', 'Front-End Developer', $103100),
('Khadija', 'Backend Developer', $193000),
('Joseph', 'Game Developer', $11500);
SELECT * FROM developers;
You should have a table with the records as shown:
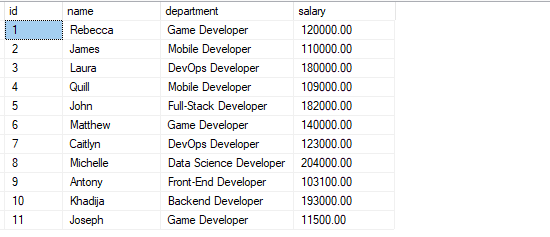
Example 1: Order By
Use the rank function to assign ranks to the data. An example query is as shown:
The query above should give output as shown:
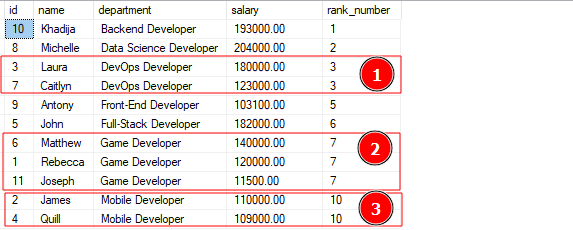
The output above shows that the function assigned the rows from similar departments a similar rank value. Notice the function skips some rank values depending on the number of values having the same rank.
For example, from the rank of 7, the function jumps to rank 10, as rank 8 and 9 are assigned to the two consecutive rank 7 values.
Example 2: Partition By
Consider the example below. It uses the rank function to assign a rank to the developers in the same department.
The query above starts by partitioning the rows according to their departments. Next, the order by clause sorts the records in each partition by the salary in descending order.
The resulting output is as shown:
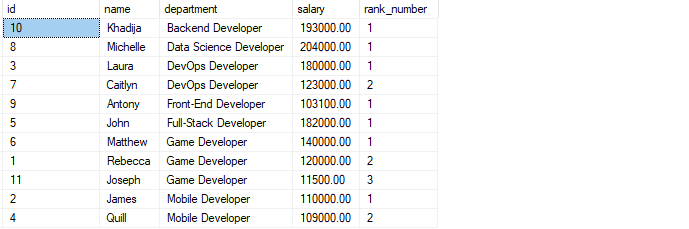
Conclusion
In this guide, we covered how to work with the rank function in SQL Server, allowing you to partition and rank rows.
Thanks for reading!
from https://ift.tt/3qBcjXd



0 Comments