


To get started, you must have MySQL installed on your system with its utilities: MySQL workbench and command-line client shell. After that, you should have some data or values in your database tables as duplicates. Let’s explore this with some examples. First of all, open your command-line client shell from your desktop taskbar and type your MySQL password upon asked.

We have found different methods to find duplicated in a table. Have a look at them one by one.
Search Duplicates in a Single Column
First, you must know about the syntax of the query used to check and count duplicates for a single column.
Here is the explanation of the above query:
- Column: Name of the column to be checked.
- COUNT(): the function used to count many duplicate values.
- GROUP BY: the clause used to group all rows according to that particular column.
We have created a new table called ‘animals’ in our MySQL database ‘data’ having duplicate values. It has six columns with different values in it, e.g., id, Name, Species, Gender, Age, and Price providing information regarding different pets. Upon calling this table using the SELECT query, we get the below output on our MySQL command-line client shell.
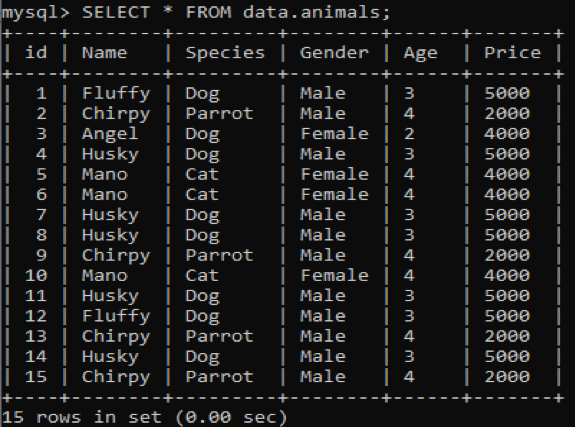
Now, we will try to find the redundant and repeated values from the above table by using the COUNT and GROUP BY clause in the SELECT query. This query will count the Names of pets which are located less than 3 times in the table. After that, it will display those Names as below.

Using the same query to get different results while changing the COUNT number for Names of pets as shown below.

To get results for a total of 3 duplicate values for Names of pets as shown below.

Search Duplicates in Multiple Columns
The syntax of the query to check or count duplicates for multiple columns is as follows:
Here is the explanation of the above query:
- col1, col2: name of the columns to be checked.
- COUNT(): the function used to count several duplicate values.
- GROUP BY: the clause used to group all rows according to that specific column.
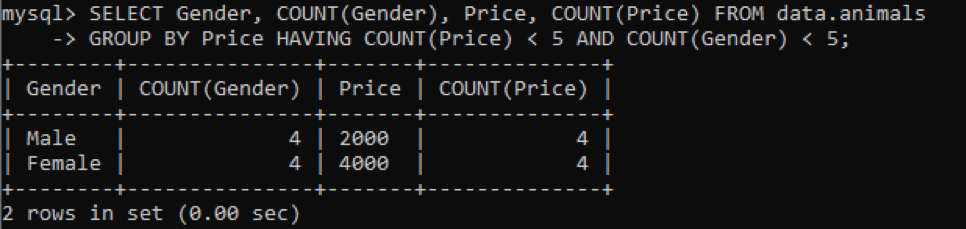
We have been using the same table called ‘animals’ having duplicate values. We got the below output while utilizing the above query for checking the duplicate values in multiple columns. We have been checking and counting the duplicate values for columns Gender and Price while grouped by the column Price. It will show the pet genders and their prices which are residing in the table as duplicates not more than 5.
Search Duplicates in Single Table Using INNER JOIN
Here is the basic syntax for finding duplicates in a single table:
Here is the narrative of the overhead query:
- Col: the name of the column to be checked and selected for duplicates.
- Temp: keyword to apply inner join on a column.
- Table: name of the table to be checked.
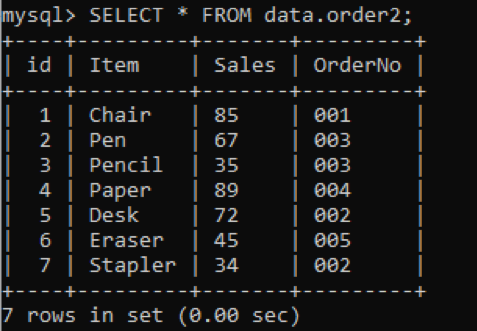
We have a new table, ‘order2’ with duplicate values in the column OrderNo as shown below.
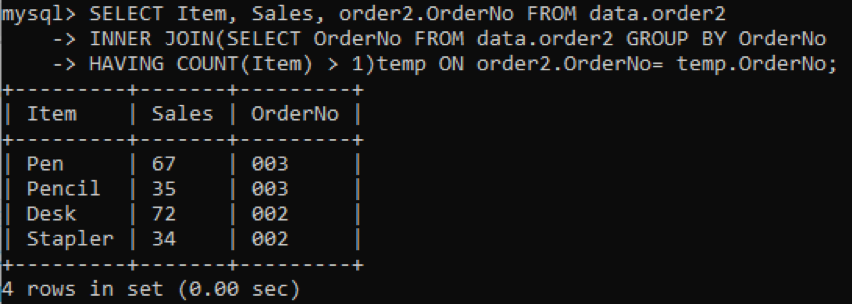
We are selecting three columns: Item, Sales, OrderNo to be shown in the output. While the column OrderNo is used to check duplicates. The inner join will select the values or rows having the values of Items more than one in a table. Upon executing, we will get the results below.
Search Duplicates in Multiple Tables Using INNER JOIN
Here is the simplified syntax for finding duplicates in multiple tables:
Here is the description of the overhead query:
- col: name of the columns to be checked and selected.
- INNER JOIN: the function used to Join two tables.
- ON: used to join two tables according to provided columns.
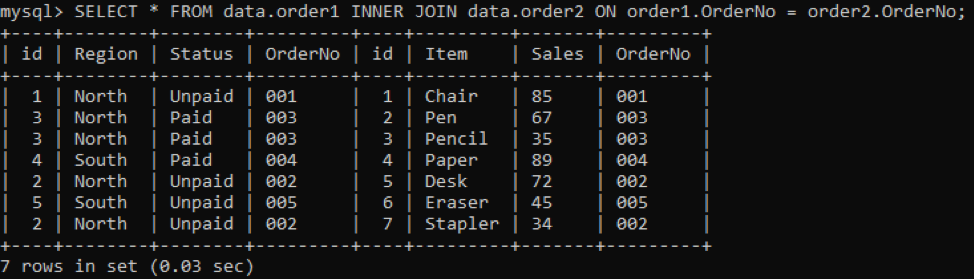
We have two tables, ‘ order1’ and ‘order2’, in our database having the ‘OrderNo’ column in both as displayed below.

We will be using the INNER join to combine the duplicates of two tables according to a specified column. The INNER JOIN clause will get all the data from both the tables by joining them, and the ON clause will relate the same name columns from both tables, e.g., OrderNo.
To get the particular columns in an output, try the below command:

Conclusion
We could now search for multiple copies in one or several tables of MySQL information and recognize the GROUP BY, COUNT, and INNER JOIN function. Make sure that you have built the tables properly and also that the right columns are chosen.
from Linux Hint https://ift.tt/2OmlolW



0 Comments