


This is a follow-up article to the previous one. We will cover how to refine the query, formulate more complex search criteria with different parameters, and understand the Apache Solr query page’s different web forms. Also, we will discuss how to post-process the search result using different output formats such as XML, CSV, and JSON.
Querying Apache Solr
Apache Solr is designed as a web application and service that runs in the background. The result is that any client application can communicate with Solr by sending queries to it (the focus of this article), manipulating the document core by adding, updating, and deleting indexed data, and optimizing core data. There are two options — via dashboard/web interface or using an API by sending a corresponding request.
It is common to use the first option for testing purposes and not for regular access. The figure below shows the Dashboard from the Apache Solr Administration User Interface with the different query forms in the web browser Firefox.
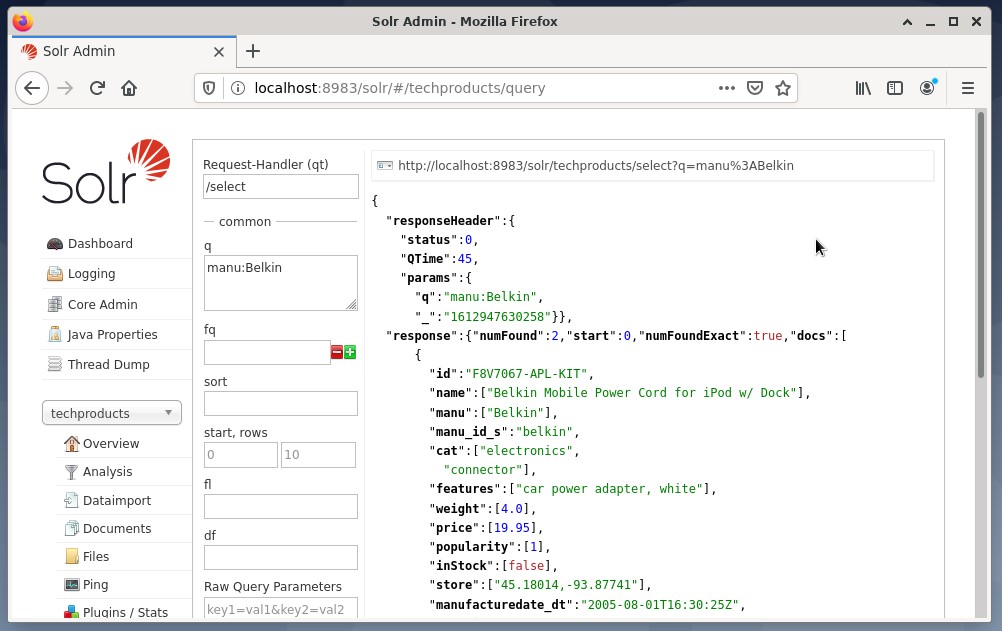
First, from the menu under the core selection field, choose the menu entry “Query”. Next, the dashboard will display several input fields as follows:
- Request handler (qt):
Define which kind of request you would like to send to Solr. You can choose between the default request handlers “/select” (query indexed data), “/update” (update indexed data), and “/delete” (remove the specified indexed data), or a self-defined one. - Query event (q):
Define which field names and values to be selected. - Filter queries (fq):
Restrict the superset of documents that can be returned without affecting the document score. - Sort order (sort):
Define the sort order of the query results to either ascending or descending - Output window (start and rows):
Limit the output to the specified elements - Field list (fl):
Limits the information included in a query response to a specified list of fields. - Output format (wt):
Define the desired output format. The default value is JSON.
Clicking on the Execute Query button runs the desired request. For practical examples, have a look below.
As the second option, you can send a request using an API. This is an HTTP request that can be sent to Apache Solr by any application. Solr processes the request and returns an answer. A special case of this is connecting to Apache Solr via Java API. This has been outsourced to a separate project called SolrJ [7] — a Java API without requiring an HTTP connection.
Query syntax
The query syntax is best described in [3] and [5]. The different parameter names directly correspond with the names of the entry fields in the forms explained above. The table below lists them, plus practical examples.
Query Parameters Index
| Parameter | Description | Example |
|---|---|---|
| q | The main query parameter of Apache Solr — the field names and values. Their similarity scores document to terms in this parameter. | Id:5 cars:*adilla* *:X5 |
| fq | Restrict the result set to the superset documents that match the filter, for example, defined via Function Range Query Parser | model id,model |
| start | Offsets for page results (begin). The default value of this parameter is 0. | 5 |
| rows | Offsets for page results (end). The value of this parameter is 10 by default | 15 |
| sort | It specifies the list of fields separated by commas, based on which the query results are to be sorted | model asc |
| fl | It specifies the list of the fields to return for all the documents in the result set | model id,model |
| wt | This parameter represents the type of response writer we wanted to view the result. The value of this is JSON by default. | json xml |
Searches are done via HTTP GET request with the query string in the q parameter. The examples below will clarify how this works. In use is curl to send the query to Solr that is installed locally.
- Retrieve all the datasets from the core cars
curl http://localhost:8983/solr/cars/query?q=*:*
- Retrieve all the datasets from the core cars that have an id of 5
curl http://localhost:8983/solr/cars/query?q=id:5
- Retrieve the field model from all the datasets of the core cars
Option 1 (with escaped &):curl http://localhost:8983/solr/cars/query?q=id:*\&fl=modelOption 2 (query in single ticks):
curl 'http://localhost:8983/solr/cars/query?q=id:*&fl=model' - Retrieve all datasets of the core cars sorted by price in descending order, and output the fields make, model, and price, only (version in single ticks):
curl http://localhost:8983/solr/cars/query -d '
q=*:*&
sort=price desc&
fl=make,model,price ' - Retrieve the first five datasets of the core cars sorted by price in descending order, and output the fields make, model, and price, only (version in single ticks):
curl http://localhost:8983/solr/cars/query -d '
q=*:*&
rows=5&
sort=price desc&
fl=make,model,price ' - Retrieve the first five datasets of the core cars sorted by price in descending order, and output the fields make, model, and price plus its relevance score, only (version in single ticks):
curl http://localhost:8983/solr/cars/query -d '
q=*:*&
rows=5&
sort=price desc&
fl=make,model,price,score ' - Return all stored fields as well as the relevance score:
curl http://localhost:8983/solr/cars/query -d '
q=*:*&
fl=*,score '
Furthermore, you can define your own request handler to send the optional request parameters to the query parser in order to control what information is returned.
Query Parsers
Apache Solr uses a so-called query parser — a component that translates your search string into specific instructions for the search engine. A query parser stands between you and the document that you are searching for.
Solr comes with a variety of parser types that differ in the way a submitted query is handled. The Standard Query Parser works well for structured queries but is less tolerant of syntax errors. At the same time, both the DisMax and Extended DisMax Query Parser are optimized for natural language-like queries. They are designed to process simple phrases entered by users and to search for individual terms across several fields using different weighting.
Furthermore, Solr also offers so-called Function Queries that allow a function to be combined with a query in order to generate a specific relevance score. These parsers are named Function Query Parser and Function Range Query Parser. The example below shows the latter one to pick all the data sets for “bmw” (stored in the data field make) with the models from 318 to 323:
q=make:bmw&
fq=model:[318 TO 323] '
Post-processing of results
Sending queries to Apache Solr is one part, but post-processing the search result from the other one. First, you can choose between different response formats — from JSON to XML, CSV, and a simplified Ruby format. Simply specify the corresponding wt parameter in a query. The code example below demonstrates this for retrieving the dataset in CSV format for all the items using curl with escaped &:
The output is a comma-separated list as follows:

In order to receive the result as XML data but the two output fields make and model, only, run the following query:
The output is different and contains both the response header and the actual response:

Wget simply prints the received data on stdout. This allows you to post-process the response using standard command-line tools. To list a few, this contains jq [9] for JSON, xsltproc, xidel, xmlstarlet [10] for XML as well as csvkit [11] for CSV format.
Conclusion
This article shows different ways of sending queries to Apache Solr and explains how to process the search result. In the next part, you will learn how to use Apache Solr to search in PostgreSQL, a relational database management system.
About the authors
Jacqui Kabeta is an environmentalist, avid researcher, trainer, and mentor. In several African countries, she has worked in the IT industry and NGO environments.
Frank Hofmann is an IT developer, trainer, and author and prefers to work from Berlin, Geneva, and Cape Town. Co-author of the Debian Package Management Book available from dpmb.org
Links and References
- [1] Apache Solr, https://lucene.apache.org/solr/
- [2] Frank Hofmann and Jacqui Kabeta: Introduction to Apache Solr. Part 1, http://linuxhint.com
- [3] Yonik Seelay: Solr Query Syntax, http://yonik.com/solr/query-syntax/
- [4] Yonik Seelay: Solr Tutorial, http://yonik.com/solr-tutorial/
- [5] Apache Solr: Querying Data, Tutorialspoint, https://www.tutorialspoint.com/apache_solr/apache_solr_querying_data.htm
- [6] Lucene, https://lucene.apache.org/
- [7] SolrJ, https://lucene.apache.org/solr/guide/8_8/using-solrj.html
- [8] curl, https://curl.se/
- [9] jq, https://github.com/stedolan/jq
- [10] xmlstarlet, http://xmlstar.sourceforge.net/
- [11] csvkit, https://csvkit.readthedocs.io/en/latest/
from Linux Hint https://ift.tt/3c3nRKf



0 Comments