


This article shows you how to find duplicates in data and remove the duplicates using the Pandas Python functions.
In this article, we have taken a dataset of the population of different states in the United States, which is available in a .csv file format. We will read the .csv file to show the original content of this file, as follows:
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
print(df_state)
In the following screenshot, you can see the duplicate content of this file:
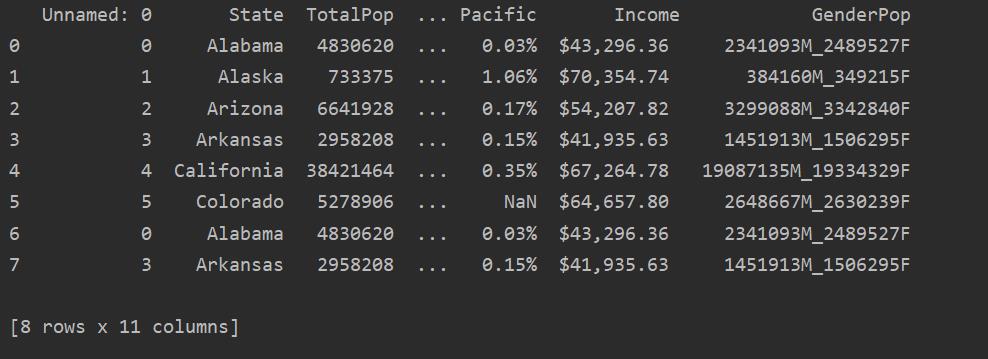
Identifying Duplicates in Pandas Python
It is necessary to determine whether the data you are using has duplicated rows. To check for data duplication, you can use any of the methods covered in the following sections.
Method 1:
Read the csv file and pass it into the data frame. Then, identify the duplicate rows using the duplicated() function. Finally, use the print statement to display the duplicate rows.
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicated()]
print("\n\nDuplicate Rows : \n {}".format(Dup_Rows))

Method 2:
Using this method, the is_duplicated column will be added to the end of the table and marked as ‘True’ in the case of duplicated rows.
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
df_state["is_duplicate"]= df_state.duplicated()
print("\n {}".format(df_state))
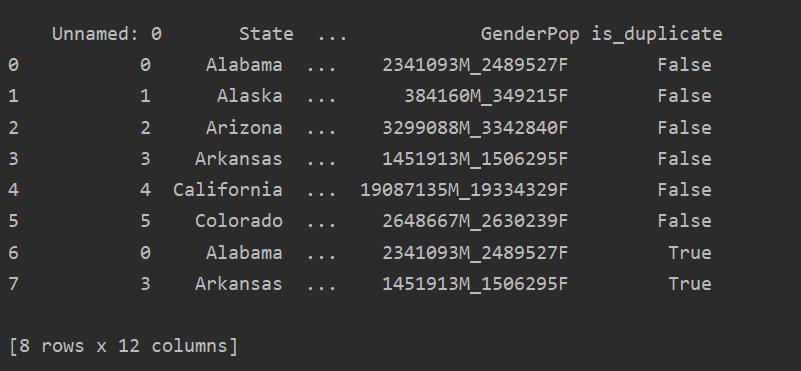
Dropping Duplicates in Pandas Python
Duplicated rows can be removed from your data frame using the following syntax:
drop_duplicates(subset=’’, keep=’’, inplace=False)
The above three parameters are optional and are explained in greater detail below:
keep: this parameter has three different values: First, Last and False. The First value keeps the first occurrence and removes subsequent duplicates, the Last value keeps only the last occurrence and removes all previous duplicates, and the False value removes all duplicated rows.
subset: label used to identify the duplicated rows
inplace: contains two conditions: True and False. This parameter will remove duplicated rows if it is set to True.
Remove Duplicates Keeping Only the First Occurrence
When you use “keep=first,” only the first row occurrence will be kept, and all other duplicates will be removed.
Example
In this example, only the first row will be kept, and the remaining duplicates will be deleted:
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicated()]
print("\n\nDuplicate Rows : \n {}".format(Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates(keep='first')
print('\n\nResult DataFrame after duplicate removal :\n', DF_RM_DUP.head(n=5))
In the following screenshot, the retained first row occurrence is highlighted in red and the remaining duplications are removed:
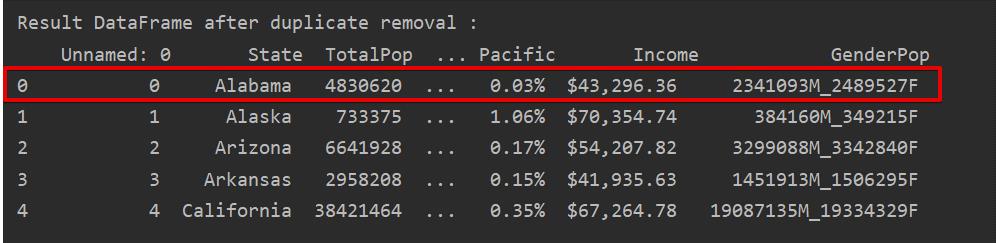
Remove Duplicates Keeping Only the Last Occurrence
When you use “keep=last,” all duplicate rows except the last occurrence will be removed.
Example
In the following example, all duplicated rows are removed except only the last occurrence.
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicated()]
print("\n\nDuplicate Rows : \n {}".format(Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates(keep='last')
print('\n\nResult DataFrame after duplicate removal :\n', DF_RM_DUP.head(n=5))
In the following image, the duplicates are removed and only the last row occurrence is kept:

Remove All Duplicate Rows
To remove all duplicate rows from a table, set “keep=False,” as follows:
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicated()]
print("\n\nDuplicate Rows : \n {}".format(Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates(keep=False)
print('\n\nResult DataFrame after duplicate removal :\n', DF_RM_DUP.head(n=5))
As you can see in the following image, all duplicates are removed from the data frame:

Remove Related Duplicates from a Specified Column
By default, the function checks for all duplicated rows from all the columns in the given data frame. But, you can also specify the column name by using the subset parameter.
Example
In the following example, all related duplicates are removed from the ‘States’ column.
df_state=pd.read_csv("C:/Users/DELL/Desktop/population_ds.csv")
Dup_Rows = df_state[df_state.duplicated()]
print("\n\nDuplicate Rows : \n {}".format(Dup_Rows))
DF_RM_DUP = df_state.drop_duplicates(subset='State')
print('\n\nResult DataFrame after duplicate removal :\n', DF_RM_DUP.head(n=6))

Conclusion
This article showed you how to remove duplicated rows from a data frame using the drop_duplicates() function in Pandas Python. You can also clear your data of duplication or redundancy using this function. The article also showed you how to identify any duplicates in your data frame.
from Linux Hint https://ift.tt/2OX2KBP



0 Comments