


Indices are specialized search tables used by databank hunt engines to accelerate query results. An index is a reference to the information in a table. For example, if the names in a contact book are not alphabetized, you would have to go down every row and search through every name before you reach the specific phone number that you are searching for. An index speeds up the SELECT commands and WHERE phrases, performing data entry in the UPDATE and INSERT commands. Regardless of whether indexes are inserted or deleted, there is no impact on the information contained in the table. Indexes can be special in the same way that the UNIQUE limitation helps to avoid replica records in the field or set of fields for which the index exists.
General Syntax
The following general syntax is used to create indexes.
To begin working on indexes, open the pgAdmin of Postgresql from the application bar. You will find the ‘Servers’ option displayed below. Right-click this option and connect it to the database.
As you can see, the database ‘Test’ is listed in the ‘Databases’ option. If you do not have one, right-click ‘Databases,’ navigate to the ‘Create’ option, and name the database according to your preferences.
Expand the ‘Schemas’ option, and you will find the ‘Tables’ option listed there. If you do not have one, right-click on it, navigate to ‘Create,’ and click the ‘Table’ option to create a new table. Since we have already created the table ‘emp’ you can see it in the list.
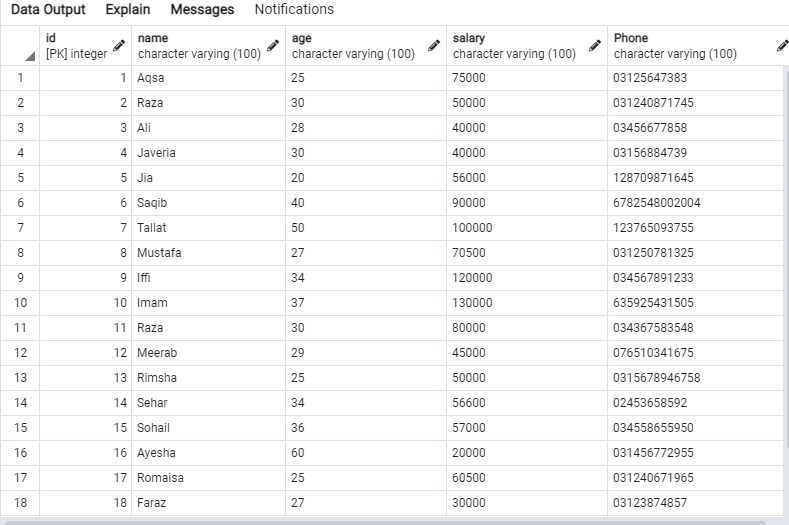
Try the SELECT query in the Query Editor to fetch the records of the ‘emp’ table, as shown below.

The following data will be in the ‘emp’ table.
Create Single-Column Indexes
Expand the ‘emp’ table to find various categories, e.g., Columns, Constraints, Indexes, etc. Right-click ‘Indexes,’ navigate to the ‘Create’ option, and click ‘Index’ to create a new index.
Construct an index for the given ‘emp’ table, or eventuated display, using the Index dialog window. Here, there are two tabs: ‘General’ & ‘Definition.’ In the ‘General’ tab, insert a specific title for the new index in the ‘Name’ field. Pick the ‘tablespace’ under which the new index will be stored using the drop-down list next to ‘Tablespace.’ As in the ‘Comment’ area, make index comments here. To begin this process, navigate to the ‘Definition’ tab.
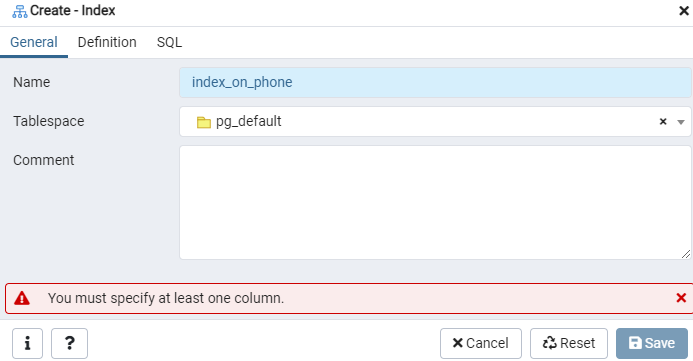
Here, specify the ‘Access Method’ by selecting the index type. After that, to create your index as ‘Unique,’ there are several other options listed there. In the ‘Columns’ Area, tap on the ‘+’ sign, and add the column names to be used for indexing. As you can see, we have been applying indexing only to the ‘Phone’ column. To begin, select the SQL section.
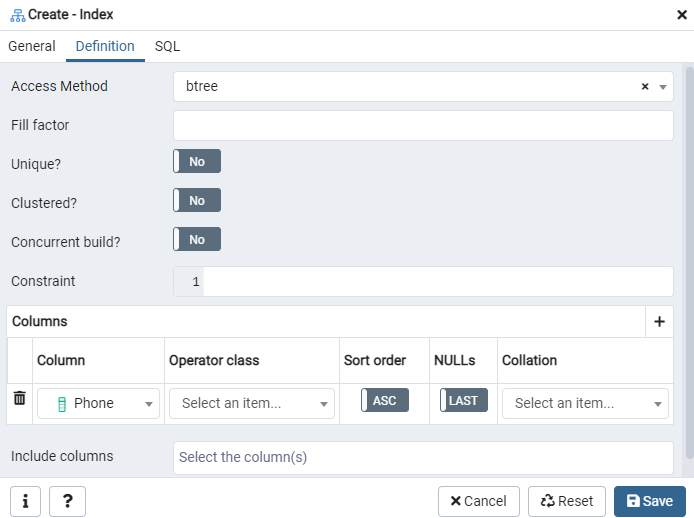
The SQL tab shows the SQL command that has been created by your inputs throughout the Index dialogue. Click the ‘Save’ button to create the index.
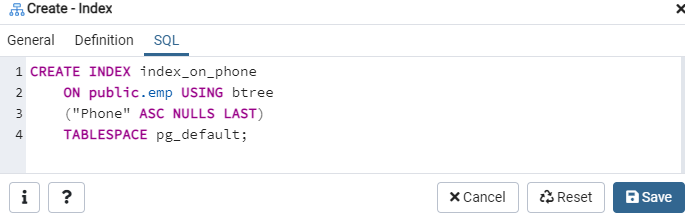
Again, go to the ‘Tables’ option, and navigate to the ‘emp’ table. Refresh the ‘Indexes’ option, and you will find the newly created ‘index_on_phone’ index listed in it.
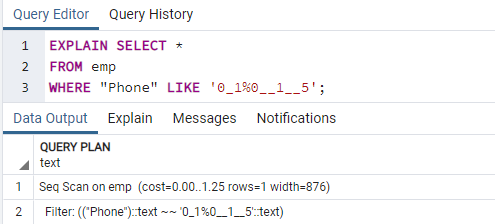
Now, we will execute the EXPLAIN SELECT command to check the results for the indexes with the WHERE clause. This will result in the following output, which says, ‘Seq Scan on emp.’ You may wonder why this happened while you are using indexes.
Reason: The Postgres planner can decide not to have an index for various reasons. The strategist makes the best decisions most of the time, even though the reasons are not always clear. It is fine if an index search is used in some queries, but not in all. The entries returned from either table may vary, depending on the fixed values returned by the query. Because this occurs, a sequence scan is almost always quicker than an index scan, indicating that perhaps the query planner was right in determining that the cost of running the query this way is reduced.
Create Multiple Column Indexes
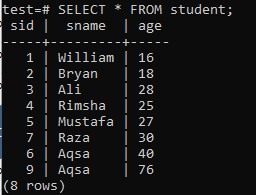
To create multiple-column indexes, open the command-line shell and consider the following table ‘student’ to start working on indexes with multiple columns.
Write the following CREATE INDEX query in it. This query will create an index named ‘new_index’ in the ‘sname’ and ‘age’ columns of the ‘student’ table.

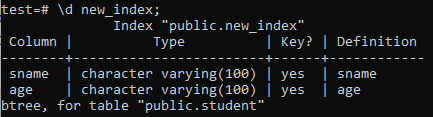
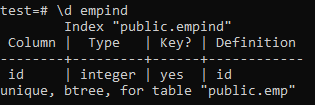
Now, we will list the properties and attributes of the newly created ‘new_index’ index using the ‘\d’ command. As you can see in the picture, this is a btree-type index that was applied to the ‘sname’ and ‘age’ columns.
Create UNIQUE Index
To construct a unique index, assume the following ‘emp’ table.
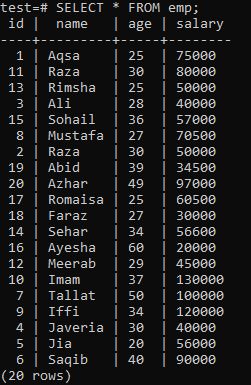
Execute the CREATE UNIQUE INDEX query in the shell, followed by the index name ‘empind’ in the ‘name’ column of the ‘emp’ table. In the output, you can see that the unique index cannot be applied to a column with duplicate ‘name’ values.

Be sure to apply the unique index only to columns that contain no duplicates. For the ‘emp’ table, you may assume that only the ‘id’ column contains unique values. So, we will apply a unique index to it.
![]()
The following are the attributes of the unique index.
Drop Index
The DROP statement is used to remove an index from a table.
![]()
Conclusion
While indexes are designed to improve the efficiency of databases, in some cases, it is not possible to use an index. When using an index, the following rules must be considered:
- Indexes should not be cast off for small tables.
- Tables with a lot of large-scale batch upgrade/update or addition/insertion operations.
- For columns with a substantial percentage of NULL values, indexes cannot be jumble-
- sale.
- Indexing should be avoided with regularly manipulated columns.
from Linux Hint https://ift.tt/3crG8B6



0 Comments