


Assume that you are the owner of a big provision shop in the county where you live. Assume that you live in a large area, which is not a commercial area. You are not the only one with a provision shop in the area; you have a few competitors. And then it occurs to you that you should record the telephone numbers of your customers in an exercise book. Of course, the exercise book is small, and you cannot record all the phone numbers for all your customers.
So you decide to record only the phone numbers of your regular customers. And so you have a table with two columns. The column on the left has the names of customers, and the column on the right has the corresponding phone numbers. In this way, there is a mapping between customer names and phone numbers. The right column of the table can be considered as the core hash table. Customer names are now called keys, and the phone numbers are called values. Note that when a customer goes on transfer, you will have to cancel his row, allowing the row empty or be replaced with that of a new regular customer. Also note that with time, the number of regular customers may increase or decrease, and so the table may grow or shrink.
As another example of mapping, assume that there is a club of farmers in a county. Of course, not all the farmers will be members of the club. Some members of the club will not be regular members (in attendance and contribution). The bar-man may decide to record the names of members and their choice of drink. He develops a table of two columns. In the left column, he writes the names of the club members. In the right column, he writes the corresponding choice of drink.
There is a problem here: there are duplicates in the right column. That is, the same name of a drink is found more than once. In other words, different members drink the same sweet drink or the same alcoholic drink, while other members drink a different sweet or alcoholic drink. The bar-man decides to solve this problem by inserting a narrow column between the two columns. In this middle column, beginning from the top, he numbers the rows beginning from zero (i.e. 0, 1, 2, 3, 4, etc.), going down, one index per row. With this, his problem is solved, as a member name now maps to an index, and not to the name of a drink. So, as a drink is identified by an index, a customer name is mapped to the corresponding index.
The column of values (drinks) alone forms the basic hash table. In the modified table, the column of indices and their associated values (with or without duplicates) form a normal hash table – full definition of a hash table is given below. The keys (first column) do not necessarily form part of the hash table.
As another example again, consider a network server where a user from his client computer can add some information, delete some information, or modify some information. There are many users for the server. Each username corresponds to a password stored in the server. Those who maintain the server can see the usernames and corresponding password, and so be able to corrupt the work of the users.
So the owner of the server decides to produce a function that encrypts a password before it is stored. A user logs into the server, with his normal understood password. However, now, each password is stored in an encrypted form. If anybody sees an encrypted password and tries to login using it, it will not work, because logging in, receives an understood password by the server, and not an encrypted password.
In this case, the understood password is the key, and the encrypted password is the value. If the encrypted password is in a column of encrypted passwords, then that column is a basic hash table. If that column is preceded by another column with indices beginning from zero, so that each encrypted password, is associated with an index, then both the column of indices and the encrypted password column, form a normal hash table. The keys are not necessarily part of the hash table.
Note, in this case, that each key, which is an understood password, corresponds to a user name. So, there is a user name that corresponds to a key that is mapped to an index, which is associated with a value that is an encrypted key.
The definition of a hash function, the full definition of a hash table, the meaning of an array, and other details are given below. You need to have knowledge in pointers (references) and linked lists, in order to appreciate the rest of this tutorial.
Meaning of Hash Function and Hash Table
Array
An array is a set of consecutive memory locations. All the locations are of the same size. The value in the first location is accessed with the index, 0; the value in the second location is accessed with the index, 1; the third value is accessed with the index, 2; fourth with index, 3; and so on. An array cannot normally increase or shrink. In order to change the size (length) of an array, a new array has to be created, and corresponding values copied to the new array. The values of an array are always of the same type.
Hash Function
In software, a hash function is a function that takes a key and produces a corresponding index for an array cell. The array is of a fixed size (fixed length). The number of keys is of arbitrary size, usually larger than the size of the array. The index resulting from the hash function is called a hash value or a digest or a hash code or simply a hash.
Hash Table
A hash table is an array with values, to whose indices, keys are mapped. The keys are indirectly mapped to the values. In fact, the keys are said to be mapped to the values, since each index is associated with a value (with or without duplicates). However, the function which does mapping (i.e. hashing) relates keys to the array indices and not really to the values, as there might be duplicates in the values. The following diagram illustrates a hash table for the names of people and their phone numbers. The array cells (slots) are called buckets.
Notice that some buckets are empty. A hash table must not necessarily have values in all its buckets. The values in the buckets must not necessarily be in ascending order. However, the indices with which they are associated are in ascending order. The arrows indicate the mapping. Notice that the keys are not in an array. They do not have to be in any structure. A hash function takes any key, and hashes out an index for an array. If there is no value in the bucket associated with the index hashed, a new value may be put in that bucket. The logical relationship is between the key and the index, and not between the key and the value associated with the index.
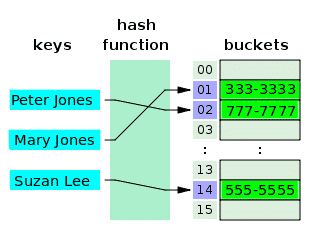
The values of an array, like the ones of this hash table, are always of the same data type. A hash table (buckets) can connect keys to the values of different data types. In this case, the values of the array are all pointers, pointing to different value types.
A hash table is an array with a hash function. The function takes a key and hashes a corresponding index, and so connects keys to values, in the array. The keys do not have to be part of the hash table.
Why Array and not Linked List for Hash Table
The array for a hash table can be replaced by a linked list data structure, but there would be a problem. The first element of a linked list is naturally at index, 0; the second element is naturally at index, 1; the third is naturally at index, 2; and so on. The problem with the linked list is that to retrieve a value, the list has to be iterated through, and this takes time. Accessing a value in an array is by random access. Once the index is known, the value is obtained without iteration; this access is faster.
Collision
The hash function takes a key and hashes the corresponding index, to read the associated value, or to insert a new value. If the purpose is to read a value, there is no issue (no problem), so far. However, if the purpose is to insert a value, the hashed index may already have an associated value, and that is a collision; the new value cannot be put where there is already a value. There are ways for solving collision – see below.
Why Collision Occurs
In the provision shop example above, the customer names are the keys, and the names of the drinks are the values. Notice that the customers are too many, while the array has a limited size, and cannot take all the customers. So, only the drinks of regular customers are stored in the array. The collision would occur when a non-regular customer becomes regular. Customers for the shop form a large set, while the number of buckets for customers in the array is limited.
With hash tables, it is the values for the keys that are very likely, that are recorded. When a key that was not likely, becomes likely, there would probably be a collision. In fact, collision always occurs with hash tables.
Collision Resolution Basics
Two approaches to collision resolution are called Separate Chaining and Open Addressing. In theory, the keys should not be in the data structure or should not be part of the hash table. However, both approaches require that the key column precedes the hash table and becomes part of the overall structure. Instead of keys being in the keys column, pointers to the keys may be in the keys column.
A practical hash table includes a keys column, but this key column is not officially part of the hash table.
Either approach for resolution can have empty buckets, not necessarily at the end of the array.
Separate Chaining
In separate chaining, when a collision occurs, the new value is added to the right (not above or below) of the collided value. So two or three values end up having the same index. Rarely more than three should have the same index.
Can more than one value really have the same index in an array? – No. So in many cases, the first value for the index is a pointer to a linked list data structure, which holds the one, two, or three collided values. The following diagram is an example of a hash table for separate chaining of customers and their phone numbers:
The empty buckets are marked with the letter x. The rest of the slots have pointers to linked lists. Each element of the linked list has two data fields: one for the customer name and the other for the phone number. Conflict occurs for the keys: Peter Jones and Suzan Lee. The corresponding values consist of two elements of one linked list.
For conflicting keys, the criterion to insert value is the same criterion used to locate (and read) the value.
Open Addressing
With open addressing, all values are stored in the bucket array. When conflict occurs, the new value is inserted in an empty bucket new the corresponding value for the conflict, following some criterion. The criterion used to insert a value at conflict is the same criterion used to locate (search and read) the value.
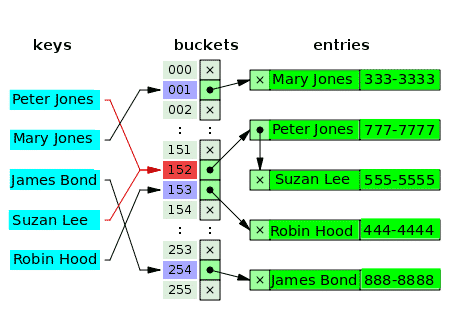
The following diagram illustrates conflict resolution with open addressing:
 The hash function takes the key, Peter Jones and hashes the index, 152, and stores his phone number at the associated bucket. After some time, the hash function hashes the same index, 152 from the key, Suzan Lee, colliding with the index for Peter Jones. To resolve this, the value for Suzan Lee is stored in the bucket of the next index, 153, which was empty. The hash function hashes the index, 153 for the key, Robin Hood, but this index has already been used to resolve the conflict for a previous key. So the value for Robin Hood is placed in the next empty bucket, which is that of index 154.
The hash function takes the key, Peter Jones and hashes the index, 152, and stores his phone number at the associated bucket. After some time, the hash function hashes the same index, 152 from the key, Suzan Lee, colliding with the index for Peter Jones. To resolve this, the value for Suzan Lee is stored in the bucket of the next index, 153, which was empty. The hash function hashes the index, 153 for the key, Robin Hood, but this index has already been used to resolve the conflict for a previous key. So the value for Robin Hood is placed in the next empty bucket, which is that of index 154.
Methods of Resolving Conflicts for Separate Chaining and Open Addressing
Separate chaining has its methods of resolving conflicts, and open addressing also has its own methods of resolving conflicts.
Methods for resolving Separate Chaining Conflicts
The methods for separate chaining hash tables are briefly explained now:
Separate Chaining with Linked Lists
This method is as explained above. However, each element of the linked list must not necessarily have the key field (e.g. customer name field above).
Separate Chaining with List Head Cells
In this method, the first element of the linked list is stored in a bucket of the array. This is possible, if the data type for the array, is the element of the linked list.
Separate Chaining with other Structures
Any other data structure, such as the Self-Balancing Binary Search Tree that supports the required operations, can be used in place of the linked list – see later.
Methods for resolving Open Addressing Conflicts
A method for resolving conflict in open addressing is called probe sequence. Three well-known probe sequences are briefly explained now:
Linear Probing
With linear probing, when a conflict occurs, the nearest empty bucket below the bucket at conflict, is looked for. Also, with linear probing, both the key and its value are stored in the same bucket.
Quadratic Probing
Assume that conflict occurs at index H. The next empty slot (bucket) at index H + 12 is used; if that is already occupied, then the next empty one at H + 22 is used, if that is already occupied, then the next empty one at H + 32 is used, and so on. There are variants to this.
Double Hashing
With double hashing, there are two hash functions. The first one computes (hashes) the index. If a conflict occurs, the second one uses the same key to determine how far down the value should be inserted. There is more to this – see later.
Perfect Hash Function
A perfect hash function is a hash function that cannot result in any collision. This can happen when the set of keys is relatively small, and each key maps to a particular integer in the hash table.
In ASCII Character Set, upper case characters can be mapped to their corresponding lower case letters using a hash function. Letters are represented in the computer memory as numbers. In ASCII Character Set, A is 65, B is 66, C is 67, etc. and a is 97, b is 98, c is 99, etc. To map from A to a, add 32 to 65; to map from B to b, add 32 to 66; to map from C to c, add 32 to 67; and so on. Here, the upper case letters are the keys, and the lower case letters are the values. The hash table for this can be an array whose values are the associated indices. Remember, buckets of the array can be empty. So buckets in the array from 64 to 0 can be empty. The hash function simply adds 32 to the upper case code number to obtain the index, and hence the lower case letter. Such a function is a perfect hash function.
Hashing from Integer to Integer Indices
There are different methods for hashing integer. One of them is called the Modulo Division Method (Function).
The Modulo Division Hashing Function
A function in computer software is not a mathematical function. In computing (software), a function consists of a set of statements preceded by arguments. For the Modulo Division Function, the keys are integers and are mapped to indices of the array of buckets. The set of keys is large, so only keys that are very likely to occur in the activity would be mapped. So collisions occur when unlikely keys must be mapped.
In the statement,
20 / 6 = 3R2
20 is the dividend, 6 is the divisor, and 3 remainder 2 is the quotient. The remainder 2 is also called the modulo. Note: it is possible to have a modulo of 0.
For this hashing, the table size is usually a power of 2, e.g. 64 = 26 or 256 = 28, etc. The divisor for this hashing function is a prime number close to the array size. This function divides the key by the divisor and returns the modulo. The modulo is the index of the array of buckets. The associated value in the bucket is a value of your choice (value for the key).
Hashing Variable Length Keys
Here, keys of the key set are texts of different lengths. Different integers can be stored in the memory using the same number of bytes (the size of an English character is a byte). When different keys are of different byte sizes, they are said to be of variable length. One of the methods for hashing variable lengths is called Radix Conversion Hashing.
Radix Conversion Hashing
In a string, each character in the computer is a number. In this method,
Hash Code (index) = x0ak−1+x1ak−2+…+xk−2a1+xk−1a0
Where (x0, x1, …, xk−1) are the characters of the input string and a is a radix, e.g. 29 (see later). k is the number of characters in the string. There is more to this – see later.
Keys and Values
In a key/value pair, a value may not necessarily be a number or text. It can also be a record. A record is a list written horizontally. In a key/value pair, each key may actually be referring to some other text or number or record.
Associative Array
A list is a data structure, where the list items are related, and there is a set of operations that operate on the list. Each list item may consist of a pair of items. The general hash table with its keys can be considered as a data structure, but it is more of a system than a data structure. The keys and their corresponding values are not very dependent on one another. They are not very related to one another.
On the other hand, an associative array is a similar thing, but keys and their values are very dependent on one another; they are very related to one another. For example, you can have an associative array of fruits and their colors. Each fruit naturally has its color. The name of the fruit is the key; the color is the value. During insertion, each key is inserted with its value. When deleting, each key is deleted with its value.
An associative array is a hash table data structure composed of key/value pairs, where there is no duplicate for the keys. The values can have duplicates. In this situation, the keys are part of the structure. That is, the keys have to be stored, whereas, with the general hast table, the keys do not have to be stored. The problem of the duplicated values is naturally solved by the indices of the array of buckets. Do not confuse between duplicated values and collision at an index.
Since an associative array is a data structure, is has at least the following operations:
Associative Array Operations
insert or add
This inserts a new key/value pair into the collection, mapping the key to its value.
reassign
This operation replaces the value of a particular key to a new value.
delete or remove
This removes a key plus its corresponding value.
lookup
This operation searches for the value of a particular key and returns the value (without removing it).
Conclusion
A hash table data structure consists of an array and a function. The function is called a hash function. The function maps keys to values in the array through the indices of the array. The keys must not necessarily be part of the data structure. The key set is usually larger than the stored values. When a collision occurs, it is resolved either by the Separate Chaining Approach or the Open Addressing Approach. An associative array is a special case of the hash table data structure.
from Linux Hint https://ift.tt/2PeZIFB



0 Comments